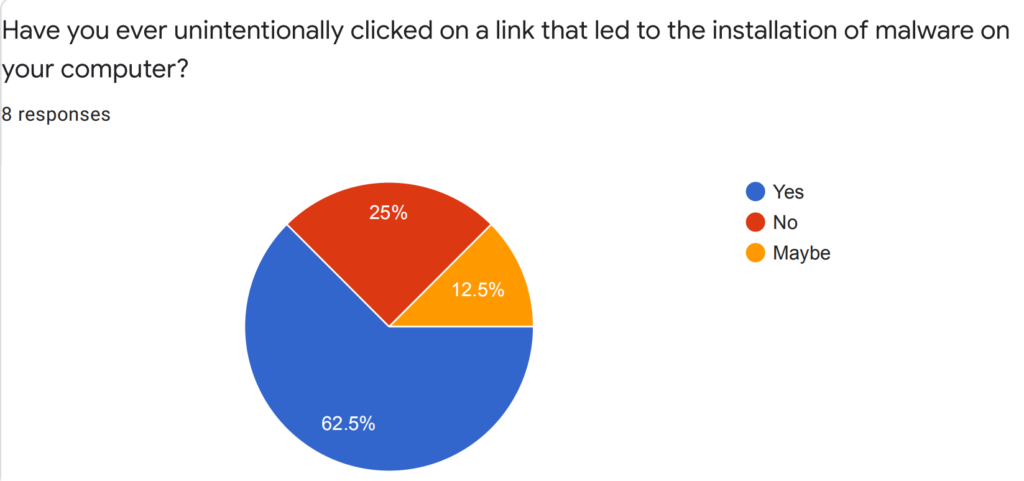
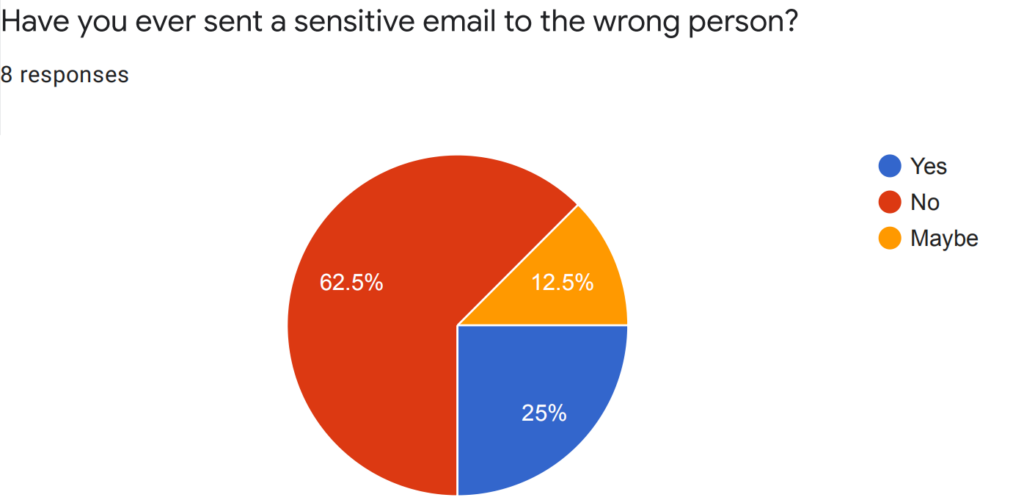
Welcome to the Winter 2022 CPSC 329/602 blog! Looking forward to some fun and interesting discussions.
Please reserve the topic for your blog post by adding a comment to this post, stating the topic you plan to cover, a short justification, and one or more links to external cites as evidence that your topic has indeed occurred in the last 7 days. We will approve your requests or offer comments if it is not deemed to be suitable. The main criteria for suitability are relevance to the course, whether the topic is sufficiently current, and whether it has already been covered by another student.
Please post your topic reservation requests at most 72 hours before your posting date and at least 24 hours, excluding weekends. For example, if you are posting on a Monday make sure to submit your reservation request by Friday at the latest. I will be sure to approve any outstanding requests by 4:30 PM every Monday through Friday.
When you are ready to make your post, please create a new post as opposed to commenting on this one – comments on this post will be reserved for topic reservations and approvals. Note that you can post any time on the day you reserved.
The price of Bitcoin plunged to its lowest point in two years. Coinbase, one of the largest cryptocurrency exchanges, lost value on the stock market. Even stablecoins — cryptocurrencies that claim to be backed by the USD, and therefore perpetually worth $1 have crashed. But what does this mean for privacy and cybersecurity?
Since cryptocurrency was boosted forth to the general public’s eye, it has been a topic of controversy, with many calling it a scam, and others believing it to be the future of financial privacy and security. One of its key selling points is that crypto offers a private, and secure alternative method of moving money, in an unregulated market free of the manipulation of politicians and billionaires. However, if the past week is any indicator, crypto as a whole is quite a ways from that goal.
According to SEC Chair Gary Gensler, the recent crash has resulted in the loss of over $800 billion. This leaves those who are invested in various crypto currencies unprotected; the supposedly ‘unregulated’ market is now working against the interests of the public. But what is the source of this crash?
Many believe that the independent nature of crypto would make it resistant to inflation and various economic crises. Bitcoin has no central issuer or authority controlling it, and that independence from government, many argued, should ensure that Bitcoin would hold its value through economic dips, international wars or drastic policy changes. We saw Bitcoin prove its value when Russia began using crypto amidst their own economic crisis following its sanctions. And yet, as worldwide inflation increases, and the housing market remains inaccessible to the average middle-class family, the world has seen many crypto investors divest to survive. As a result, the ‘manipulation-free’ market saw a $300,000,000,000 liquidation overnight.
Furthermore, investors have watched as world governments have moved toward regulation. Meanwhile, ‘crypto has been shaken by a wave of hacks and security breaches, including a $600 million hack of the Ethereum sidechain Ronin’, further challenging its claim to be a paragon of financial security. Such hacks have shaken consumer confidence in crypto and slowed growth from new potential buyers entering the field.
Edward Moya, senior market analyst at Oanda, told CBS News ‘the number of real-world use cases that would bring newcomers into the crypto space seems to be slowing this year’. In his words, “There’s a belief that mainstream adoption [of Bitcoin] is taking a lot longer than people expected,” Moya said. “Right now, what we’re seeing is that the crypto market is in a wait-and-see mode.” These sentiments, combined with the state of the rest of the financial market accumulated to contribute to last week’s crash.
Whether this slide continues remains to be seen. Some believe that things will only get worse as more and more investors panic, continuing to pull out their investments. Now that the price of Bitcoin dropped below $30,000, its price corrected when evangelists “bought the dip,” or entered the market at a discounted rate. They believe that amidst its day-to-day turbulence, Bitcoin will continue its zoomed-out growth pattern that it has displayed over the last decade, hopefully taking its rightful place as the future of finance.
For my final CPSC 602 project, I wanted to create an “unessay” in the form of an educational video that would actually be (hopefully) entertaining to watch. While brainstorming, I thought of all the times I was watching TV and wanted to correct what was happening if it fell within my usual area of expertise. Through this (probably annoying) fighting with the TV, my friends and family have unwillingly gained a lot of knowledge about the functioning of the legal system in the past. So, could I expand this to information security? And furthermore, could I do it in a way that was less annoying?
In looking into how to address this, I came across Wired’s “Technique Critique” series. In watching these, I was amazed by how much I could trick myself into learning when it was hidden in a TV show clip. I decided this style of video would be the best to try to emulate in my project.
In approaching this task, I first thought of TV shows I knew addressed topics we had covered in the course. The first example, which ended up making up a significant portion of my final project was Brooklyn Nine-Nine, where the characters frequently either reference passwords or attempt to gain access to the accounts of others. One difficultly here however was actually obtaining video that would be usable, as I could only download and use videos already uploaded to YouTube. However, I managed to find a few relevant clips.
The squad tries to guess Terry’s password
Here I ran into the problem that I had only addressed one issue brought up within the course. While this would potentially be fine for other projects, my purpose here was to address a few topics so that an average TV lover could gain a broad understanding of multiple topics over the course of a fifteen minute video. Here, my approach because less sophisticated. I immediately logged on to Netflix, looked through my viewing history, and then for the longer running shows, searched “name of the show + computer/hacked/cyber/bitcoin”. Here I came up with two more clips that touched on course issues. While there were a few more, I realized my video was getting a bit long, and any longer would mean that the video would lose viewers and therefore its purpose of broad education.
While there were a few unexpected hiccups that came with video editing, I managed to create a video just under fifteen minutes which addressed password security, encryption, and VPNs/TOR in a way that was (hopefully) user accessible and engaging.
A clip from the final project (as long as this site would let me insert)
Cybersecurity refers to all the technologies, processes and attitudes that aim to protect data, devices, programs, systems and networks from cyber threats and attacks. [1] Experts take all possible measures and precautions to minimize the risk of cybercrime affecting system security.
However, we found that the fact is, most threats to organizational information systems (IS) are due to vulnerabilities and breaches caused by employees. About 72-95 per cent of cyber threats to organizations are due to users’ mistakes. Human error can occur both at home, involving your personal devices and data, and at the workplace, where its consequences can be much farther-reaching. If business data and systems are affected, the company may lose time, money, clients, partners and can even face lawsuits. [9] For years, “human error” has consistently been identified as a major contributing factor to cybersecurity breaches. Several recent reports revealed that 43% of C-Suite leaders who reported a data breach cited human error as the second major cause. The average cost of human errors in cybersecurity breaches was $3.33 million.[7]
From ransomware attacks to serious data breaches, human error invariably plays a role in information security incidents. Almost all successful cyber breaches have one variable in common: human error. Human error can manifest in a multitude of ways: from failing to install software security updates in time to having weak passwords and giving up sensitive information to phishing emails. Yet it remains true that many organizations still fail to take into consideration this important factor when thinking about their information security strategy. [2] Human errors are used by cybercriminals to effect unauthorized access, steal credentials, and infect IT systems and endpoints with malware such as ransomware. Without the human-in-the-machine effect, cybercrime would be much more difficult. Therefore, if we can fully analyze the network security problems caused by human factors, extract potential problems according to the case, reflect and correct the loopholes, and minimize the cybersecurity problems caused by human errors. Then this will have a positive effect on the entire network security environment and greatly reduce the attack methods of cyber criminals. [5]
How many cyber security incidents are caused by human error?
There are three types of human error in cybersecurity. The first type is unintentional human error. Errors of this type result from a lack of knowledge or skill, or perhaps distraction. Some human error, however, is intentional: an IT worker might deliberately take a risk with their organization’s systems that could cause a cybersecurity incident. These errors often violate ethics and laws on data stewardship. The third kind of human error is even more intentional. Malicious error occurs when an employee deliberately makes a system vulnerable in order to steal (exfiltrate) confidential data.
There are the 800 largest data breaches to occur between 2007 and 2019 in the US, how many were the result of human error? The answer is 291, roughly 36%. However, another 47% may have been due to human error as well. Of the 291, 102 are selected for further analysis since enough data exists about them to make that possible. In this dataset, the author identifies three different types of human error in cybersecurity: skills-based mistakes (mistakes in repetitive, familiar activities that do not require conscious thought), rule-based mistakes (mistakes in using a known rule or procedure to respond to a familiar situation) and knowledge-based mistakes (mistakes in using slow, conscious, analytical processes to solve new and unfamiliar problems) and matches them to three different types of vulnerabilities that often cause breaches: system misconfiguration errors, skills-based errors and rule-based errors.
Relevant Researches
Researchers from the Old Dominion University have conducted a cross-sectional survey study of employees in different organizations. Their results suggest that gender has moderate effects on safety self-efficacy, prior experience, and computer skills, but has little effect on action cues and self-reported cybersecurity behaviors. [2]
In addition, According to the research fromVilnius University, there is a relationship between genetically informed traits such as impulsiveness and the likelihood of IT workers to accidentally cause cybersecurity breaches. These personality traits are particularly important due to the long working hours, stress and wide-ranging responsibilities entailed by IT.
Researchers from Middel Georgia StateUniversity designed a set of scenarios-based hands-on tasks to measure the cybersecurity skills of non-information technology (IT) professionals. Their study shows the importance of skills and hands-on assessment appears applicable to cybersecurity skills of non-IT professionals. Therefore, by using an expert-validated set of cybersecurity skills and scenario-driven tasks, this study established and validated a set of hands-on tasks that measure observable cybersecurity skills of non-IT professionals without bias or the high-stakes risk to IT. [3]
Survey from cyber security companies
We also surveyed several employees from the industry. Some results are showed as follow:
Our Story Map
The format of our project is the Story Map. This blog only contains part of its content. For more details about this topic and our project. Please browser our story map to explore. Link of Story Map:
[1]. aAmbrozaitytė, Laima, et al. “Human Characteristics and Genomic Factors as Behavioural Aspects for Cybersecurity. Augmented Cognition, Springer International Publishing, Cham, 2021, pp. 333–350. Lecture Notes in Computer Science.
[2]. Anwar, Mohd, et al. “Gender Difference and Employees’ Cybersecurity Behaviors.” Computers in Human Behavior, vol. 69, 2017, pp. 437–443.
[3]. Melissa Carlton, et al. “Mitigating Cyber Attacks through the Measurement of Non-IT Professionals’ Cybersecurity Skills.” Information Management & Computer Security, vol. 27, no. 1, 2019, pp. 101–121.
[4]. Cornejo, Gabriel A. Human Errors in Data Breaches: An Exploratory Configurational Analysis, 2021.
[5]. Hoske, Mark T. “Advice from Cybersecurity Incident: Cybersecurity Incident: Human Errors Enabled It, but the Triconex Safety Controller Shut down the Plant as Designed, Say Experts with Schneider Electric and ARC Advisory Group. But It’s Still a Call to Action for Industry. Have You Implemented Changes since Then?” Control Engineering, vol. 65, no. 4, 2018, p. 10.
[6]. Maalem Lahcen, Rachid Ait, et al. “Review and Insight on the Behavioral Aspects of Cybersecurity.” Cybersecurity, vol. 3, no. 1, 2020, pp. 1–18.
[7]. Malatji, Masike, et al. “Validation of a Socio-Technical Management Process for Optimising Cybersecurity Practices.” Computers & Security, vol. 95, 2020, pp. 101846–17.
[8]. Khalid Khan, Shah, et al. “A Conceptual System Dynamics Model for Cybersecurity Assessment of Connected and Autonomous Vehicles.” Accident Analysis and Prevention, vol. 165, 2022, p. 106515.
[9]. Kim, Hee Eun, et al. “Systematic Development of Scenarios Caused by Cyber-Attack Induced Human Errors in Nuclear Power Plants.” Reliability Engineering & System Safety, vol. 167, 2017, pp. 290–301.
[10]. Nobles, Calvin. “Botching Human Factors in Cybersecurity in Business Organizations.” Holistica : Journal of Business and Public Administration, vol. 9, no. 3, 2018, pp. 71–88.
[11]. Pollini, Alessandro, et al. “Leveraging Human Factors in Cybersecurity: an Integrated Methodological Approach.” Cognition, Technology & Work, 2021, pp. 1–20.
[12]. Sawyer, Ben D, and Peter A Hancock. “Hacking the Human: The Prevalence Paradox in Cybersecurity.” Human Factors, vol. 60, no. 5, 2018, pp. 597–609.
[13]. Jeremy Straub, “Physical security and cyber security issues and human error prevention for 3D printed objects: detecting the use of an incorrect printing material,” Proc. SPIE 10220, Dimensional Optical Metrology and Inspection for Practical Applications VI, 102200K (15June 2017); https://doi-org.ezproxy.lib.ucalgary.ca/10.1117/12.2264578
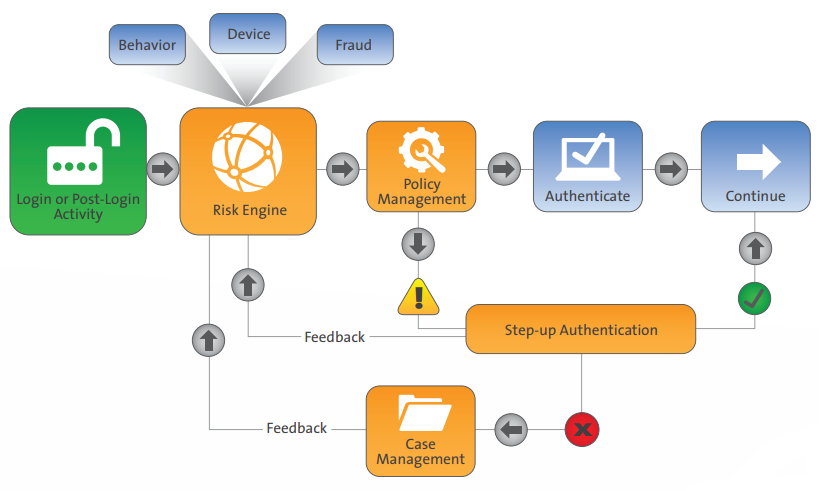
Security has become a crucial part of the digital era and organizations are moving towards advanced techniques to keep their networks secure from malicious threats. With new advancements in security technology, there is always a level of uncertainty about its efficacy and whether there exist loopholes in its design for exploitation. Authentication mechanisms using single or multiple factors, such as password protection, certificate validation, and bio metrics, are still vulnerable when they are static. Contextual knowledge, an essential aspect of adaptive authentication, plays a key role to dynamically validate users while minimizing risk in real time. In this way, adaptive authentication is an ideal solution for modern network security. Although many organizations are quite skeptical about this innovative technology, numerous examples, theoretical systems, industrial systems, and academic surveys shed light on the benefits of adaptive authentication.
What is Adaptive Authentication?
Adaptive authentication is a form of multi-factor authentication wherein it selects only a specific set of authentication factors based on user profiles that depend on several contextual aspects, such as Geo location, proximity to devices, and bio metrics. To achieve this, adaptive authentication deploys an ML (machine learning) algorithm to maintain and dynamically update these authentication factors based on predefined criteria and real time information during each interaction with the user. Such information used may include history of authentication, access failure/success rate, the device used to access, and more.
On a broad level, authentication factors can be categorized into three areas: knowledge-based, location-based, and behavior-based. Knowledge-based factors include methods such as user passwords and pins; location-based factors may include the Geo-location of the user; and behavior-based factors can include using sensors for bio metrics, such as touch id and a retinal scan, and subjective information like patterns of device usage. On the other hand, single factor authentication, although faster, does not provide the highest security.
Adapting to Adaptive Authentication
Many companies are hesitant to adopt adaptive authentication in favor of a fixed security mechanism that provides transparency for monitoring and evaluation. However, these traditional security mechanisms can be exploited when sensitive information is leaked, such as passwords, key pins, and key cards. Adaptive authentication can ensure more reliability as it strategize responses based on an estimated risk derived from user profiles and maintains risk scores from user transactions over time. An entity is deemed risky when abnormalities begin to emerge in authentication; an adaptive authentication model would select the most suitable factors for assessment and can deny access due to these abnormalities. Based on context and requirements, they can be classified as,
Trust-Based Authentication: To overcome the contradiction between privacy and security by enabling trust with selective authentication schemes to prevent sensitive data leakage.
Risk-Based Authentication: To identify the threat before performing evaluation which ensures reliability and effectiveness.
Context-Based Continuous Authentication: Contextual verification of users throughout sessions by monitoring for service usage behavior even after initial authentication.
Industrial Applications
Although there are challenges and uncertainties with theoretical proposals and prototypes, there are companies who are currently implementing adaptive authentication for their products with more adaptive authentication technologies to be released in the near future. As the value for security keeps increasing, organizations are moving towards AI solutions and dynamic security protocols.
Silent Authentication for e-Commerce
The French multinational company Thales, which provides technical services for the aerospace industry, has recently announced a product that uses silent authentication for e-commerce delivery via drones. The company aims to achieve continuous authentication in real time with a seamless experience using the way phones are used, user location, gait (a person’s manner of walking), patterns of actions, and surrounding signals. They aim to achieve,
Trusted connected objects such as mobile becoming the main form for ID
Seamless user experience (e.g., if a phone is forgotten at home, there is a temporary device at the office with transferred updated personal phone data)
Personalized experience (e.g., automatic lighting based on mood)
Adaptive Verification Based on Risk
IBM Security Verify Adaptive Access is a system that helps organizations with secure verification by balancing risk considerations with user experience. A risk calculation engine (IBM Trusteer) developed by IBM is used to assess user profiles throughout digital interactions to provide risk-based policy editor, protect SAAS, analyze threat intelligence, detect suspicious user behavior, assess device hygiene (for malware/viruses) and behavioral bio metric abnormalities.
Benefits
Adaptive authentication leverages three primary concepts:
Contextual knowledge
Real-time threat analysis
Continuous assessment for adaption after authentication
All three notions play a significant role in modern security. With advancements in technology, we now have the means to analyze a variety of data sources through modern sensors along with the computational capability through AI while enabling trust-based security to enhance non-intrusiveness into personal data.
Usability is another aspect to consider in terms of business platforms. User experiences can be improved with personalized accessibility features that do not tire the customers with lengthy authorization protocols while also increasing performance. The environment also plays a key role in determining security processes as certain domains like the medical industry and transportation industry are time sensitive and serious. Finally, continuous monitoring ensures hackers and imposters who may duplicate actual user identities to pass initial authentication, are captured through behavioral analysis during communication with the network.
Opportunities
It is important to note that AI is becoming ever more prominent in computer science and security fields. It is certainly plausible that AI will become incredibly influential in network security as well. From a business perspective, it is becoming more prudent to venture into adaptive authentication technologies as early as possible to gain a market advantage over competitors in strategy and revenue.
Companies already have the physical means and processes that are needed to be brought together to achieve the successful implementation of adaptive authentication techniques. An ISMG (Information Security Media Group) survey in 2019 indicated that adaptive authentication topped the list of authentication investments. The survey also highlighted that only 10% of all financial institutions showed confidence in their security features as 96% of them still use legacy systems. Moreover, 37% percent of these financial institutions have an active initiative that is working towards these technologies. Hence, adaptive authentication is going to be a game changer for organizations needing strong defense to guard customer and enterprise data.
The study of graphs consisting of nodes connected by edges representing some pairwise relation are of interest to security experts who wish to model complex computer or server networks. My paper describes several applications of graph theoretic results in cybersecurity, one of which is introduced here.
The healthcare industry is a frequent target of cyberattacks due to overworked hospital staff, a problem only exacerbated as a result of Covid 19. Confidential patient data can be sold or ransomed for a lot of money, and hospitals often rely on outdated technology to keep information secure. The concept of a dominating set may be utilized when a lack of sufficient resources makes it impossible to guard every component of a system.
We might model defenders as mobile guards defending a network, where a guard on vertex v can protect against an attack on any server adjacent to v by an edge. This set of vertices is known as the neighborhood of v, denoted N(v). If every vertex is protected in such a way by at least one guard, the network is said to be dominated. The problem of determining the size of a minimum dominating set is an exact solution for efficiently defending networks against worm propagation.[1]
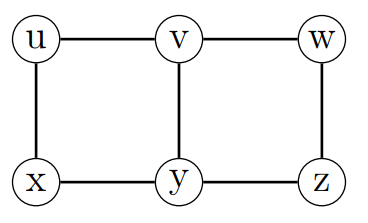
Consider the small grid below. Guards located at vertices u, w, and y would dominate the graph, but so would two guards located at x and w. Since no vertex is adjacent to all other vertices, a dominating set of size 1 cannot exist, and hence the minimum domination number of the graph is 2.
Figure 1: A 2×3 grid.
A dominating set S is secure if exchanging a vertex outside of the dominating set for its neighbour in S results in a new dominating set. In our application, the network remains dominated even after a mobile guard were to move from his node to a neighboring node. In figure 1, the set {u, w, y} satisfies the secure dominating set condition but {x, w} does not: if vertex z were to be attacked, the guard on w would have to move, leaving v uncovered.
Figure 2: The Bloom Graph B3,6.[1]
Although determining the minimum size of a dominating or secure dominating set is NP-complete, exact constructions can be found in linear time for certain families of graphs. One such family is bloom graphs (above), whose symmetry and structure makes them appealing for large-scale parallel computer networks. It was shown in [1] that if Bm,n is a bloom graph with m ‘layers’ of n ‘petals’ each, the smallest possible secure dominating set has size n(ceiling(m/2)).
With a secure dominating set in place, safeguarding the nodes of the network and monitoring for any potential deficiencies becomes a significantly easier task.
References:
[1] Angel, D. (2022). Application of graph domination to defend medical information networks against cyber threats. Journal of Ambient Intelligence and Humanized Computing. 10.1007/s12652-022-03730-2.
[2] Lesniak, L., Chartrand, G., and Zhang, P. (2015). Graphs & Digraphs. United States: CRC Press.
[3] Webb, J., Docemmilli, F., and Bonin, M. (2015). Graph Theory Applications in Network Security. SSRN Electronic Journal. 10.2139/ssrn.2765453.
UNODC logo, United Nations Office on Drugs and Crime, retrieved April 12 2022 from <https://www.un.org/en/messengers-peace/unodc>.
My final project focused on the international enforcement of laws against cybercrimes. Specifically, it looked to the successes and failures of existing regimes which deal with cybercrime, and then attempted to posit suggestions for both the existing cybercrime framework, and potential new treaty documents.
Overview of Cybercrimes
A number of difficulties inherent to cybercrimes become apparent upon researching them. Cybercrimes are difficult to define, and there is a lack of international consensus on what does and does not constitute a cybercrime.1 The consequences and perpetrators also vary dramatically, from lone-wolf criminals targeting elderly citizens to organized crime and international terrorist cells.2 Cybercrimes are a growth industry with high returns and low risk, and are on pace to continue to grow in the coming years with the increasing availability of new anonymity and obfuscation technology.3
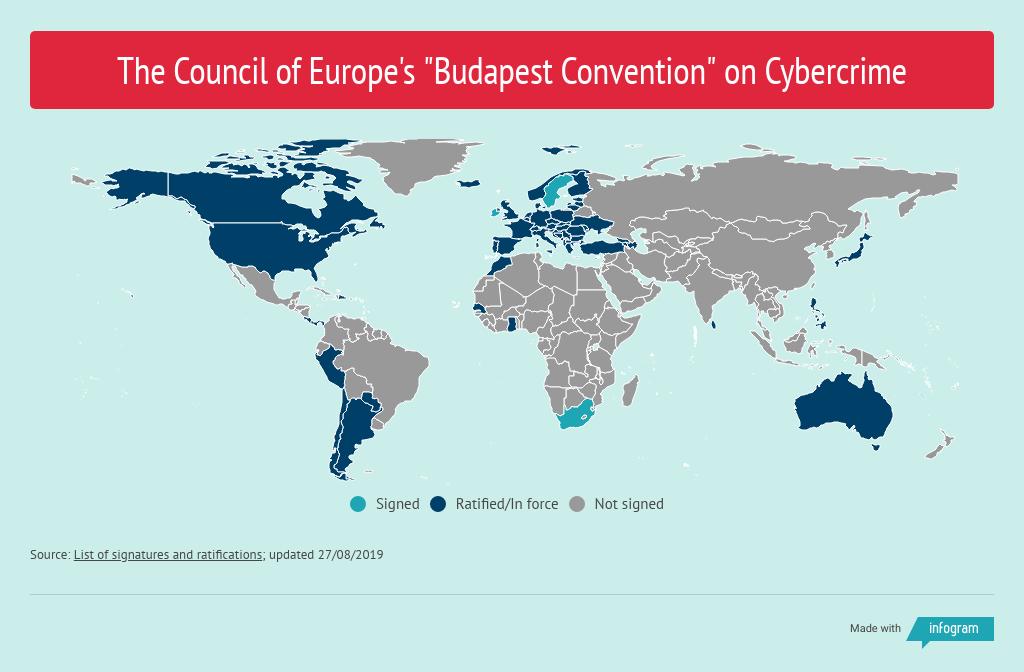
By way of response to cybercrimes, the main international agreement undertaken by the global community is the Budapest Convention, a document which specifies individual and cooperative goals to be undertaken by signatory states.4 International agencies such as INTERPOL, EUROPOL, and the World Economic Forum are also engaged against cybercrime.
Despite the organized response to cybercrimes, response and conviction rates remain perilously low, with some countries (such as the United States) reporting an approximately 1% rate of arrests for cybercrime, and other countries unable to provide any statistics at all.5 Research shows that the primary driver for these abysmal statistics are enforcement gaps between local and international actors, enforcement barrier, jurisdictional issues, and difficulties with enforcement inherent to the legal system (such as procedural issues, time, and capacity shortcomings).6
So what has actually worked?
“Budapest Convention on Crime” Council of Europe, retrieved April 12 2022 from <https://infogram.com/budapest-convention-on-cybercrime-1h8n6m5ljz5z2xo?live>
A number of common factors emerge when analyzing trends in cybercrime enforcement. Historically, the greatest indicators of success in cybercrime enforcement have been direct sharing of information between states, speed, available contact points, and participation of private and third party groups.7 Conviction rates from case law in multiple jurisdictions point to a similar idea, in addition to standardizing evidentiary procedures.8 These factors are not all that surprising, and in fact are provided for within the text of the Budapest Convention. Yet we know that the Budapest Convention insofar has not been particularly successful. So what can be done to increase the rate of success in enforcing cybercrime laws?
Substance and structure
“CITES Logo”, CITES, retrieved April 04 2022 from <https://mantawatch.com/site/2013/02/will-cites-protect-this-threatened-species/>.
By looking to more successful frameworks within the international law sphere, we can potentially glean some ideas on how to improve or adapt the Budapest Convention. One such framework is the Convention on International Trade of Endangered Species, or CITES. The circumstances and structure of the two frameworks are quite similar, however the principal different between CITES and the Budapest Convention is that CITES allows for more freedom in undertaking unilateral actions by states to keep with their treaty obligations. By allowing signatory parties a similar freedom to craft their own methods to meet treaty obligations, the Budapest Convention might be improved. These improvements might take the form of an additional agreement on top of the Budapest Convention while using the existing convention as a backstop (similar to PIPEDA in Canada), or changing the writing of the existing convention to be less permissive and more imperative.
Another area that is worth considering is reward diplomacy. The enforcement mechanisms of the current Budapest Convention amount to little more than shaming on an international scale which, while sometimes effective, are not always an ideal enforcement tool. Reward diplomacy, wherein obligations are framed as an opportunity to gain rather than an obligation to avoid punishment, is an attractive alternative. In particular, reward diplomacy is more effective at fostering cooperation and reciprocal action between nations, both of which are indicators of successful cybercrimes enforcement.9 Reward diplomacy can take many forms, including technology-for-compliance exchanges, payment agreements, or investment by both states and private third parties. Reward diplomacy would also be much easier to incorporate into the existing wording of the Budapest convention, avoiding the considerable delay and uncertainty of creating new international legislation.
Conclusion
Cybercrimes are difficult to deal with. The damage they cause is varied and can be significant, yet enforcing them implicates all sorts of jurisdictional and procedural headaches. While it is unlikely that any single piece of legislation or treaty will be able to fully wipe them out, changes that encourage more cooperation, speed, and information sharing will hopefully lead to long lasting positive changes in the international enforcement of cybercrimes.
Sources
[1] Ajayi E.F.G, “Challenges to enforcement of cybercrimes law and policy” (2016) 6:1 J Internet and Information Systems 1 at 2.
[2] ENISA, “Threat Landscape 2021” (2021) at 7, online (pdf): European Agency for Cybersecurity < www.enisa.europa.eu/publications/enisa-threat-landscape-2021>.
[3] Ajayi, supra note 1.
[4] Convention on Cybercrime, November 23 2001, ETS 185.
[5] Allison Peters & Amy Jordan, “Countering the Cyber Enforcement Gap: Strengthening Global Capacity on Cybercrime” (2020) 10:487 J Nat Security L & P 487 at 492.
[6]Ibid at 495.
[7] See generally Pedro Verdelho, “The effectiveness of international co-operation against cybercrime: examples of good practice” (2008), online (pdf): Council of Europe < www.coe.int/t/dg1/legalcooperation/economiccrime/cybercrime/TCY/DOC-567study4-Version7_en.PDF>; Susan Brenner & Joseph Schwerha, “Transnational Evidence Gathering and Local Prosecution of International Cybercrime” (2002) 20:1 J Marshall J Computer & Info L 347 at 355-357; UNODC, “Obstacles to cybercrime investigations” (March 2019), online : UNODC < www.unodc.org/e4j/en/cybercrime/module-5/key-issues/obstacles-to-cybercrime-investigations.html>; Jan Kleijssen and Pierluigi Perri, “Cybercrime, Evidence and Territoriality: Issues and Options” (2017) 47 Netherlands Yearbook of Intl L 147.
[8] See for example United States v Okeke, No. 4:19-cr-00084 (E.D. Va. Feb. 16, 2021); R v Kalonji, 2019 ONCJ 341; R v ML & Ors CR S 63/19.
[9]Anne van Aaken & Betul Simsek “Rewarding in International Law” (2021) 115:2 American J Intl L 195 at 196.
Reading news online has become more common in Bangladesh, displacing the traditional technique of staying up to date with current events by reading printed copies of newspapers sent to one’s doorstep every morning. As a result of this fact, the number of online news portals has significantly increased as they adapt to the modern approach of maximizing profit, the potential of which has been highlighted rapidly. Even well-known and well-known newspaper companies in Bangladesh, on the other hand, utilize misleading and fraudulent headlines to attract traffic to their websites. In 2015, millions of Bangladeshis shared a news story on a popular online news portal alerting them that Abdur Razzak, their favorite actor, had died. Nonetheless, a small number of people may have picked up on the fact that the actor is dead in the latest film he was working on, rather than in real life [5]. People’s panic lasted weeks, but the practice of publishing satire and fake news with an impressive methodology of making the news appear true in order to boost website traffic skyrocketed at times. Even though Bangladesh publishes over 1000 newspapers online every day, the inundation of false and satirical news has made finding real news challenging. The fake and satirical news portals are often found to be filled with malicious intentions—having both increasing the number of visitors and stealing the visitor’s personal data to sell to third-party organizations.
Bangladesh fights with fake news [source: Daily Star]
Over the years, Natural Language Processing, a branch of Artificial Intelligence, has played an increasingly important role in comprehending written languages and delivering on-demand, useful solutions to respective problem domains, particularly in the detection of fake news. While using machine learning techniques to detect fake and satirical news in English is admirable, there has been minimal success in Bangla news. A recent study developed a Deep Neural Network architecture termed BNnet (Imran et al., 2020) to predict Bangla fake news demonstrating substantial performance, in line with the development necessary in Bangla news. However, there is still potential for improvement when it comes to detecting fake news using various deep learning architectures. We contribute to the following in this project:
Propose a novel methodology for Bangla fake news detection
Demonstrate a promising and improved detection performance of Bangla fake news by providing a comparative performance analysis among the different classifiers used
We used both embedding-based and transformer-based models to achieve our goal, with a strong emphasis on BERT Bangla [1]. We used a total of five evaluation metrics to assess the models: Accuracy, Precision, Recall, F1 Score, and Area Under the ROC Curve (AUC).
Dataset we used
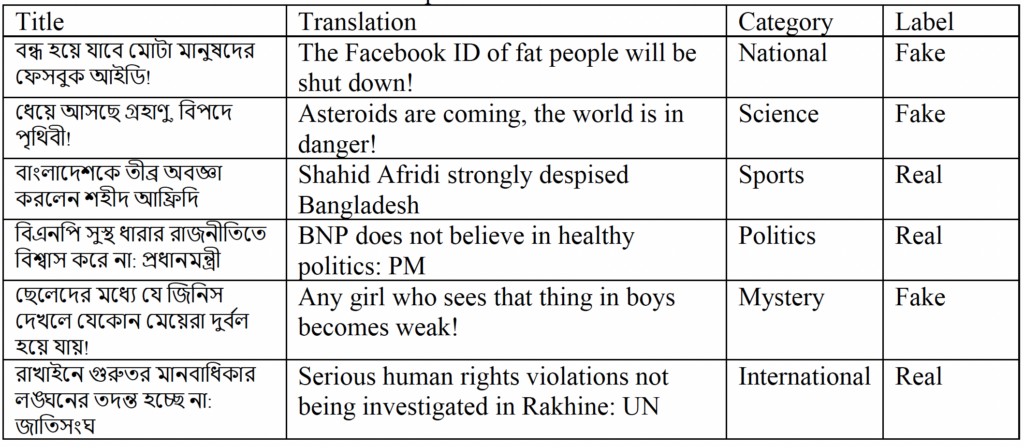
Data was gathered from numerous Bangla news portals via web scraping. We started with a list of 43 Bangla news portal websites, 25 of which are legitimate, reputable, and verified news portals, and 18 of which are satirical and fake news portals. A set of sample Bangla news is provided below:
Fig 1. Bangla Fake News Samples
Experimentation
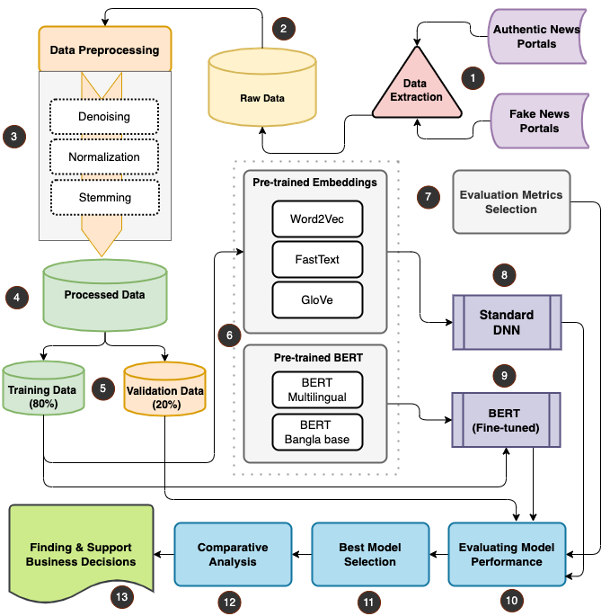
Our experiment is split into two parts: one uses embedding-based models such as word2vec [8], fastText [7], and GloVe [6], and the other uses BERT [9], a transformer-based model. Both of these steps have two sub-steps that must be completed for the experiment to be completed. The following figure 2 shows the proposed methodology of this experiment.
Fig 2. Proposed Methodology for Bangla Fake News Detection
At first, we have collected and extracted the data from various authentic and fake news portal of Bangladesh. Next, we have preprocessed data using Denoising, Normalization, and Stemming techniques to be able to use the data for training the machine learning models. Keeping the training and testing ratio as 80:20, we further then applied both pre-trained embedding algorithms and pre-trained BERT algorithms to detect the Bangla fake news. After implementing the system, we finally perform an analysis of the performance.
Results
Our results demonstrate that transformer based (BERT models) performs better than embedding based algorithms in detection of Bangla fake news. As we have used both Multilingual based BERT and Bangla based BERT, we have found that the Bangla based BERT performs better than multilingual BERT. The multilingual based BERT model provides an accuracy score of 87% for Bangla fake news detection. However, the Bangla BERT based model produces an accuracy score of 91% while the Area Under Curve (AUC) score of 98%. Lastly, based on all the analysis, evaluation metrics, and performance, it can be said that the newly proposed BNnetXtreme demonstrated a significantly improved performance in detecting Bangla fake news, and the BERT Bangla base classifier is found to be the best.
Conclusion
The citizens of Bangladesh witness fake and misleading news as they browse the internet every day. Recently, numerous incidents took place that made people victims of identity theft, losing money due to investing in fake endorsed businesses, becoming participants of communal violence, etc. Thus, fake news in the context of Bangladesh is significantly important to take into consideration for advanced research and investigation to give users a safe space in online news portals that might potentially be misleading, fake, or malicious. Furthermore, to provide the policymakers of Bangladesh to control and monitor the online space in line with mitigating the public risk and influence led by fake and misleading news. In this project, we have thus studied and experimented with a proposed methodology that can detect Bangla fake news in order to contribute to the community that is fighting fake news every day.
References
[1] Sagor Sarker, 2020, BanglaBERT: Bengali Mask Language Model for Bengali Language Understanding, URL {https://github.com/sagorbrur/bangla-bert}, accessed on Feb 10, 2021.
[2] Hossain, E., Kaysar, N., Joy, J. U., Md, A. Z., Rahman, M., & Rahman, W. (2022). A Study Towards Bangla Fake News Detection Using Machine Learning and Deep Learning. In Sentimental Analysis and Deep Learning (pp. 79-95). Springer, Singapore.
[3] George, M. Z. H., Hossain, N., Bhuiyan, M. R., Masum, A. K. M., & Abujar, S. (2021, July). Bangla Fake News Detection Based On Multichannel Combined CNN-LSTM. In 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT) (pp. 1-5). IEEE.
[4] Adib, Q. A. R., Mehedi, M. H. K., Sakib, M. S., Patwary, K. K., Hossain, M. S., & Rasel, A. A. (2021, October). A Deep Hybrid Learning Approach to Detect Bangla Fake News. In 2021 5th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT) (pp. 442-447). IEEE.
[5] Al Imran, A., Wahid, Z., & Ahmed, T. (2020, December). BNnet: A Deep Neural Network for the Identification of Satire and Fake Bangla News. In the International Conference on Computational Data and Social Networks (pp. 464-475). Springer, Cham.
[6] Pennington, J., Socher, R., & Manning, C. D. (2014, October). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
[7] Joulin, A., Grave, E., Bojanowski, P., Douze, M., Jégou, H., & Mikolov, T. (2016). Fasttext. zip: Compressing text classification models. arXiv preprint arXiv:1612.03651.
[9] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
In 2019, the Communications Security Establishment (CSE) had its mandates expanded under the CSE Act from three to five, with the two newest additions authorizing the agency to conduct “active” (offensive) and “defensive” cyber operations. My paper asked the following question: What significance does the CSE Act’s new mandates entail for the CSE’s role in enforcing Canadian cyber security? Based on findings, the CSE Act highlights the expanding capabilities that the organization has honed since gaining statutory legitimacy in 2001 to defend Canada from new and emerging threats in the cyber realm. However, the agency’s practice of secrecy does little to improve transparency on what the CSE will do with its new powers and may liberally interpret the Act.
CSE’s Addiction to Secrecy. Why? That’s Because it’s[ Statement Redacted]
Much of what we do know about the agency is due to the Edward Snowden revelations (less than 40 files!) (Clement, 2021). Much of what I have been able to assess regarding the agency’s capabilities was reliant on these files. This reveals an interesting observation: Compared to the CSE’s cousin, the National Security Agency (NSA), much less is known about the CSE. This is by design. Legislation and compartmentalization inside the agency ensure that its secrets remain unknown to the public (Walby, and Anaïs, 2012). The next paragraph goes further into this:
This highlighted sentence does not hold any secrets and neither do the other ones. This highlighted sentence does not hold any secrets and neither do the other ones.
Moving on… there are two more important reasons for this secrecy: First, statutory law provides the agency a “legal shield” to legitimately conduct its practices with less legal interference and oversight (Walby, and Anaïs, 2012, 377). Second, the CSE’s strict adherence to secrecy has been influenced by the Cold War—a period of the CSE’s history where it honed much of its skills—which pre-dates the arrival of the Canadian Charter of Rights and Freedoms and other legislation protecting individual rights (Prince, 2021).
Before the Act’s ascension into law, the CSE still developed its cyber capabilities. The Snowden Files reveal that the CSE’s capabilities in offensive and defensive cyber operations were established by the early 2010s. For example, in 2015, the CSE added the NSA’s hacking software (QUANTUM) to its toolbox for conducting its cyber targeting missions across the globe (Seglins, 2015). The Who may be its targets is not well known. The CSE’s “normal global collection” of data is also unspecific and likely intercepts Canadian information abroad and has the infrastructure to do so inside Canada, as shown by the controversial Airport Wi-Fi Data-Tracking story (Clement, 2021, 131). This begs the question of how far the CSE may intrude on Canadians’ privacy regarding the CSE Act, which The Canadian Civil Liberties Association claims will harm the public’s freedom of expression (CCLA, 2017).
Secrecy will be met with distrust and suspicion. This has been the case for Canada because oversight and transparency remain challenges to properly institutionalizing (Prince, 2021). Despite calls for greater accountability, Canada’s national security concerns since the early 2000s and has made Ottawa willing to expand the CSE and its intelligence contemporaries’ powers to conduct practices that are intrusive (Prince, 2021, 48). Since 2020, the COVID-19 pandemic has pushed the CSE to the forefront of Canadian national security to address the rising number of cyberattacks (Robinson, 2021). Undoubtedly, however, Canada’s cyber capabilities are strengthening, which is good for Canada’s internet infrastructure. But the question remains about how intrusive the CSE’s operations may be toward Canadians.
(While this concludes my blog, I recommend the following articles/books to read if this subject found to be interesting)
Pozen, David E. “Deep Secrecy,” Stanford Law Review 62, no. 2 (2010): 257-340
Carvin, Stephanie, Thomas Juneau, and Craig Forcese. Top secret Canada: Understanding the Canadian intelligence and national security community. Toronto, ON: University of Toronto Press, 2020.
Lyon, David, and David M. Wood. Big data surveillance and security intelligence: The Canadian case. Vancouver Toronto: UBC Press, 2021.
And finally, check out this fifth source:
Works Cited
CCLA. “The New Communications Security Establishment Act in Bill C-59.” Canadian Civil Liberties Association, 12 September 2017. https://ccla.org/privacy/national-security/the-new-communications-security-establishment-act-in-bill-c-59/ (Accessed 26 March 2022).
Clement, Andrew. “Limits to secrecy: What are the Communications Security Establishment’s capabilities for intercepting Canadian internet communications?.” In Big Data Surveillance and Security Intelligence: The Canadian Case. Edited by David Lyon and David Murakami Wood, 126-146. Vancouver, BC: University of British Columbia Press, 2021.
Ericson, Richard V. “The state of preemption: Managing terrorism risk through counter law.” In Risk and War on Terror. Edited by Louise Amoore and Marieke de Goede, 57-76. Oxon, UK: Routledge, 2008.
Lagassé, Philippe. “Defence intelligence and the Crown prerogative in Canada.” Canadian Public Administration 64, no. 4 (2021): 539-560.
Robinson, Bill. “Collection and Protection in the Time of Infection: The Communications Security Establishment during the COVID-19 Pandemic.” In Stress Tested: The COVID-19 pandemic and Canadian national security. Edited by Leah West, Thomas Juneau, Amarnath Amarasingam, 127-144. Calgary, AB: LCR Publishing Services, 2021.
Seglins, Dave. “Communication Security Establishment’s cyberwarfare toolbox revealed.” CBC, 23 March 2015.https://www.cbc.ca/news/canada/communication-security-establishment-s cyberwarfare-toolbox-revealed-1.3002978 (Accessed 17 March 2022).
Prince, Christopher. “On denoting and concealing in surveillance law.” In Big Data Surveillance and Security Intelligence: The Canadian Case. Edited by David Lyon and David Murakami Wood, 43-56. Vancouver, BC: University of British Columbia Press, 2021.
Walby, Kevin, and Seantel Anaïs. “Communications security establishment Canada (CSEC), structures of secrecy, and ministerial authorization after September 11.” Canadian Journal of Law & Society, 27, no. 3 (2012): 365-380.
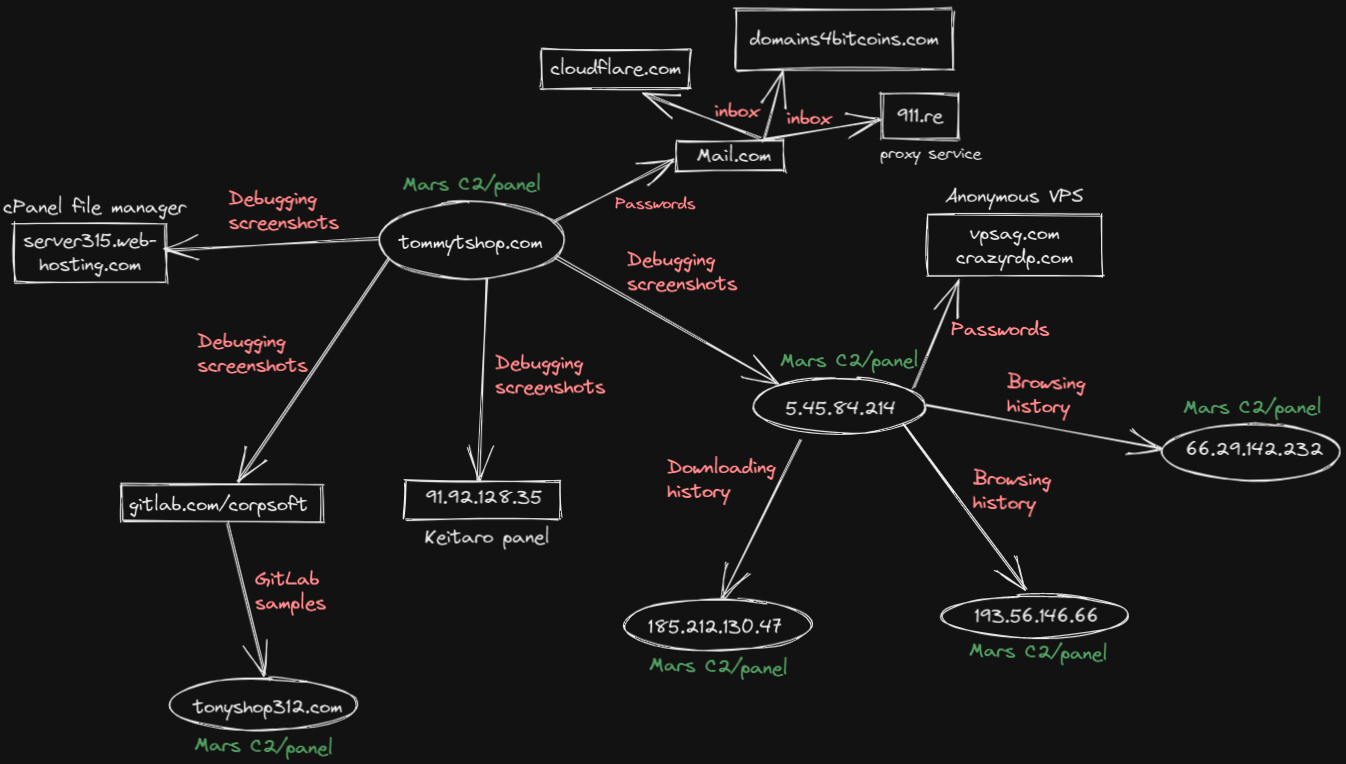
Fig 1: Diagram of the Attack Infrastructure Source: Morphisec
Mars Stealer is a piece of off-the-shelf malware going for around 160$ for a lifetime subscription on various underground forums and dark web sites. It can steal information from your browser like cookies, autofill data, and credit card info. It can steal information about your computer or even attack your cryptocurrency wallets. Furthermore, depending on the customer’s intentions, it can be configured to download something else onto the infected machine, such as more malware.
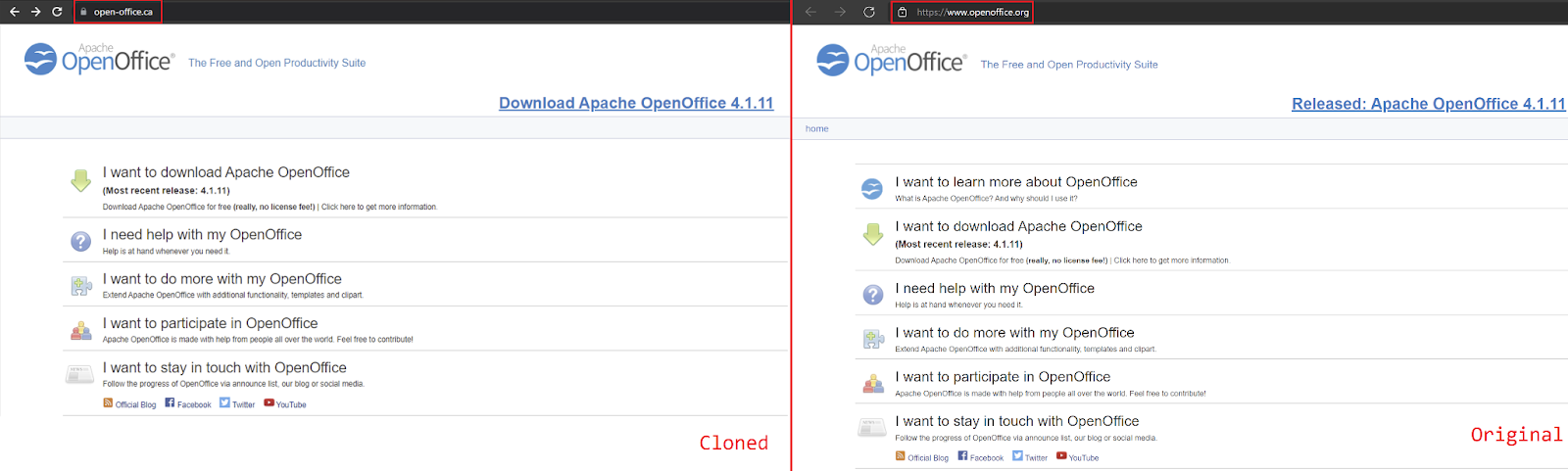
One particular attacker has set up clones of sites where you can download well-known software, and then used Google Ad Services to advertise these clones. When an unsuspecting user clicks on the ad, they are directed to this cloned site where their computer is infected with malware. The attacker is paying for these ads using stolen information, and using geographically targeted ads to target Canadians[2].
Shortly after the latest version was released, someone released a cracked version with an instruction document. Fortunately, this guide contained flaws. These flaws lead to customers improperly setting up their environments, which made investigating Mars much easier for security researchers. Researchers were able to gleam a great deal of information about the abovementioned attacker because on top of being one of those individuals with an improperly set up environment, they managed to infect their own computer while debugging, so their information was found with all the victims’ info[2].
About Mars Stealer
Mars Stealer is an evolution of an older, no longer supported information stealer known as Oski Stealer, which had a thriving community of happy customers who left positive feedback on their experiences with this ‘product’ and the support provided by the team behind it before it abruptly stopped[3]. Mars is apparently still receiving updates.
This malware has two features I thought were particularly interesting. First, it will not attack a computer within the CIS (Confederacy of Independent States). It achieves this by checking the user language ID of the region format setting against a list of IDs corresponding to countries within the CIS, including Russia, Belarus, Kazakhstan, etc.[4] Second, it has a one month expiration date; it checks its own compile time and then compares this to the current time from the system, and if it was compiled more than one month ago, it exits.[4]
Obfuscation and Detection Evasion
Mars Stealer uses some interesting techniques to avoid detection by Windows Defender as well as some more savvy tech enthusiasts who might be checking for malware.
To confuse humans, Mars obfuscates its code by encrypting the strings used in the program and also by using run-time dynamic linking. This means it is necessary to decrypt the strings using the key stored in the program, and then resolve the libraries and functions it uses in order to be able to read the code easily[3]. Furthermore, it is able to detect when it is being run in debug mode by initiating a sleep for 15 seconds. After the sleep call, it checks how much time actually passed, and if it is less than 10 seconds, that (likely) means that the sleep was skipped by a debugger, and the program exits without executing any malicious code[4].
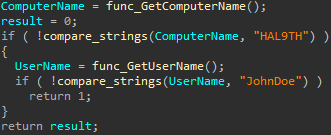
Mars also evades Windows Defender Emulation by checking the environment. Specifically, it checks whether the device name is ‘HAL9TH’ and the user is ‘JohnDoe’[4] and, as above, it immediately exits if it finds these indicators. While I appreciate the reference to the HAL 9000, there’s no way it’s this easy to beat Windows Defender, right? Right?!?(It is)
Fig 3: Emulation Check Code Source: 3xp0rt
On the plus side, I suppose we’ve learned that a good way to avoid being hit by malware would be to name your computer ‘HAL9TH’ and always use the username ‘JohnDoe’, thereby tricking any malware that checks for this emulator into not attacking you.
Finding vulnerabilities within automakers are not uncommon and don’t strike as serious, however, issues arise regarding the lack of attention in the cyber security of a vehicle. Major security flaws have been found in “smart” vehicles regarding the Combined Charging system and the keyless entry system of cars. The flaw being, the extreme lack of security.
How has the Combined Charging system affected vehicles?
Researchers from Oxford University have found a new vulnerability in electric vehicles’ Combined Charging System. They have been able attack a vehicle by cutting off the charging system 10 meters away. This was done with nothing more than “off-the-shelf technology”. The researchers named this attack “Brokenwire” and discovered that it has the ability to affect 12 million electric cars currently on the road. It has been noted that this includes electric planes, heavy-duty vehicles and ships.
The attack is done wirelessly from afar using electromagnetic interference. It disturbs essential control communication between the charger and vehicle and allows individual or fleets of vehicles to be simultaneously interrupted.
How has the keyless entry system affected vehicles?
The car manufacturing company, Honda, is known to not prioritise security and as a result, a bug has been found amongst almost all Honda and Acura vehicles. The company does not incorporate any rolling code system and only uses static code systems. Therefore, there is no protection against replay attacks and, in general, no security. With this, there is a lack of security to exploit and gain control of the vehicle. The bug is known as CVE-2022-27254 and affects all remote/wireless radio entry in Honda and Acura cars. It can allow an attacker complete control over commands such as locking, unlocking, opening trunk, controlling windows and even starting the engine. The attacker can gain a decent amount of control of the car just by capturing a signal from a key fob. If an individual locked their car and the attacker records the signal transmitted from that command, they will have the ability to replay the action. Not only that, but they also have the ability to demodulate, edit and retransmit any command they have access to.
However, Honda and Acura’s are not alone in this. Several smart cars over the years have had key fob security flaws. In 2020 researchers from the Computer Science and Industrial Cryptography and the University of Leuven in Belgium have been able to break into and steal Tesla’s from keyless fobs. They discovered that the use of Bluetooth Low Energy (BLE), an increasing network used in cars, is the cause of the security breach. The BLE was not properly secured and as a result they were able to compromise the key fob.
How can these be fixed?
It seems as though the evolution of “smart” cars has created an increasing field of threat in security. Due to the lack of prioritization attackers can easily can access and/or disrupt communication networks in vehicles. To prevent current and future cyberattacks automakers need to value security in their systems. This can be done by implementing various security measures such as rolling code, which can prevent various attackers from infiltrating vehicle systems.